Skip to content
GitLab
Menu
Projects
Groups
Snippets
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
wwwanlingxiao
LeetCodeAnimation
Commits
f1048508
Commit
f1048508
authored
Apr 17, 2020
by
程序员吴师兄
Browse files
整理文件
parent
c3aa5c59
Changes
65
Hide whitespace changes
Inline
Side-by-side
0131-Palindrome-Partitioning/Animation/Animation.gif
0 → 100644
View file @
f1048508
193 KB
0131-Palindrome-Partitioning/Article/0131-Palindrome-Partitioning.md
0 → 100644
View file @
f1048508
# LeetCode 第 131 号问题:分割回文串
> 本文首发于公众号「图解面试算法」,是 [图解 LeetCode ](<https://github.com/MisterBooo/LeetCodeAnimation>) 系列文章之一。
>
> 同步博客:https://www.algomooc.com
题目来源于 LeetCode 上第 131 号问题:分割回文串。题目难度为 Medium,目前通过率为 45.8% 。
### 题目描述
给定一个字符串
*s*
,将
*s*
分割成一些子串,使每个子串都是回文串。
返回
*s*
所有可能的分割方案。
**示例:**
```
yaml
输入
:
"
aab"
输出
:
[
[
"
aa"
,
"
b"
],
[
"
a"
,
"
a"
,
"
b"
]
]
```
###
### 题目解析
首先,对于一个字符串的分割,肯定需要将所有分割情况都遍历完毕才能判断是不是回文数。不能因为
**abba**
是回文串,就认为它的所有子串都是回文的。
既然需要将所有的分割方法都找出来,那么肯定需要用到DFS(深度优先搜索)或者BFS(广度优先搜索)。
在分割的过程中对于每一个字符串而言都可以分为两部分:左边一个回文串加右边一个子串,比如 "abc" 可分为 "a" + "bc" 。 然后对"bc"分割仍然是同样的方法,分为"b"+"c"。
在处理的时候去优先寻找更短的回文串,然后回溯找稍微长一些的回文串分割方法,不断回溯,分割,直到找到所有的分割方法。
举个🌰:分割"aac"。
1.
分割为 a + ac
2.
分割为 a + a + c,分割后,得到一组结果,再回溯到 a + ac
3.
a + ac 中 ac 不是回文串,继续回溯,回溯到 aac
4.
分割为稍长的回文串,分割为 aa + c 分割完成得到一组结果,再回溯到 aac
5.
aac 不是回文串,搜索结束
### 动画描述

### 代码实现
```
java
class
Solution
{
List
<
List
<
String
>>
res
=
new
ArrayList
<>();
public
List
<
List
<
String
>>
partition
(
String
s
)
{
if
(
s
==
null
||
s
.
length
()==
0
)
return
res
;
dfs
(
s
,
new
ArrayList
<
String
>(),
0
);
return
res
;
}
public
void
dfs
(
String
s
,
List
<
String
>
remain
,
int
left
){
if
(
left
==
s
.
length
()){
//判断终止条件
res
.
add
(
new
ArrayList
<
String
>(
remain
));
//添加到结果中
return
;
}
for
(
int
right
=
left
;
right
<
s
.
length
();
right
++){
//从left开始,依次判断left->right是不是回文串
if
(
isPalindroom
(
s
,
left
,
right
)){
//判断是否是回文串
remain
.
add
(
s
.
substring
(
left
,
right
+
1
));
//添加到当前回文串到list中
dfs
(
s
,
remain
,
right
+
1
);
//从right+1开始继续递归,寻找回文串
remain
.
remove
(
remain
.
size
()-
1
);
//回溯,从而寻找更长的回文串
}
}
}
/**
* 判断是否是回文串
*/
public
boolean
isPalindroom
(
String
s
,
int
left
,
int
right
){
while
(
left
<
right
&&
s
.
charAt
(
left
)==
s
.
charAt
(
right
)){
left
++;
right
--;
}
return
left
>=
right
;
}
}
```

\ No newline at end of file
0136-Single-Number/Animation/136.gif
0 → 100644
View file @
f1048508
446 KB
0136-Single-Number/Article/0136-Single-Number.md
0 → 100644
View file @
f1048508
# LeetCode 第 136 号问题:只出现一次的数字
> 本文首发于公众号「图解面试算法」,是 [图解 LeetCode ](<https://github.com/MisterBooo/LeetCodeAnimation>) 系列文章之一。
>
> 同步博客:https://www.algomooc.com
题目来源于 LeetCode 上第 136 号问题:只出现一次的数字。题目难度为 Easy,目前通过率为 66.8% 。
### 题目描述
给定一个
**非空**
整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
**说明:**
你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
**示例 1:**
```
输入: [2,2,1]
输出: 1
```
**示例 2:**
```
输入: [4,1,2,1,2]
输出: 4
```
### 题目解析
根据题目描述,由于加上了时间复杂度必须是 O(n) ,并且空间复杂度为 O(1) 的条件,因此不能用排序方法,也不能使用 map 数据结构。
程序员小吴想了一下午没想出来,答案是使用
**位操作Bit Operation**
来解此题。
将所有元素做异或运算,即a[1] ⊕ a[2] ⊕ a[3] ⊕ …⊕ a[n],所得的结果就是那个只出现一次的数字,时间复杂度为O(n)。
### 异或
异或运算A ⊕ B的真值表如下:
| A | B | ⊕ |
| :--- | :--: | ---: |
| F | F | F |
| F | T | T |
| T | F | T |
| T | T | F |
### 动画演示

### 进阶版
有一个 n 个元素的数组,除了两个数只出现一次外,其余元素都出现两次,让你找出这两个只出现一次的数分别是几,要求时间复杂度为 O(n) 且再开辟的内存空间固定(与 n 无关)。
#### 示例 :
输入: [1,2,2,1,3,4]
输出: [3,4]
### 题目再解析
根据前面找一个不同数的思路算法,在这里把所有元素都异或,那么得到的结果就是那两个只出现一次的元素异或的结果。
然后,因为这两个只出现一次的元素一定是不相同的,所以这两个元素的二进制形式肯定至少有某一位是不同的,即一个为 0 ,另一个为 1 ,现在需要找到这一位。
根据异或的性质
`任何一个数字异或它自己都等于 0 `
,得到这个数字二进制形式中任意一个为 1 的位都是我们要找的那一位。
再然后,以这一位是 1 还是 0 为标准,将数组的 n 个元素分成两部分。
-
将这一位为 0 的所有元素做异或,得出的数就是只出现一次的数中的一个
-
将这一位为 1 的所有元素做异或,得出的数就是只出现一次的数中的另一个。
这样就解出题目。忽略寻找不同位的过程,总共遍历数组两次,时间复杂度为O(n)。
### 动画再演示


\ No newline at end of file
0138-Copy-List-with-Random-Pointer/Animation/Animation.gif
0 → 100644
View file @
f1048508
1.38 MB
0138-Copy-List-with-Random-Pointer/Article/0138-Copy-List-with-Random-Pointer.md
0 → 100644
View file @
f1048508
# LeetCode 第 138 号问题:复制带随机指针的链表
> 本文首发于公众号「图解面试算法」,是 [图解 LeetCode ](<https://github.com/MisterBooo/LeetCodeAnimation>) 系列文章之一。
>
> 同步博客:https://www.algomooc.com
题目来源于 LeetCode 上第 138 号问题:复制带随机指针的链表。题目难度为 Medium,目前通过率为 40.5% 。
### 题目描述
给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点。
要求返回这个链表的
**深拷贝**
。
**示例:**
```
输入:
{"$id":"1","next":{"$id":"2","next":null,"random":{"$ref":"2"},"val":2},"random":{"$ref":"2"},"val":1}
解释:
节点 1 的值是 1,它的下一个指针和随机指针都指向节点 2 。
节点 2 的值是 2,它的下一个指针指向 null,随机指针指向它自己。
```
### 题目解析
1.
在原链表的每个节点后面拷贝出一个新的节点
2.
依次给新的节点的随机指针赋值,而且这个赋值非常容易 cur->next->random = cur->random->next
3.
断开链表可得到深度拷贝后的新链表
之所以说这个方法比较巧妙是因为相较于一般的解法(如使用 Hash map )来处理,上面这个解法
**不需要占用额外的空间**
。
### 动画描述

### 代码实现
我发现带指针的题目使用 C++ 版本更容易描述,所以下面的代码实现是 C++ 版本。
```
c++
class
Solution
{
public:
RandomListNode
*
copyRandomList
(
RandomListNode
*
head
)
{
if
(
!
head
)
return
NULL
;
RandomListNode
*
cur
=
head
;
while
(
cur
)
{
RandomListNode
*
node
=
new
RandomListNode
(
cur
->
label
);
node
->
next
=
cur
->
next
;
cur
->
next
=
node
;
cur
=
node
->
next
;
}
cur
=
head
;
while
(
cur
)
{
if
(
cur
->
random
)
{
cur
->
next
->
random
=
cur
->
random
->
next
;
}
cur
=
cur
->
next
->
next
;
}
cur
=
head
;
RandomListNode
*
res
=
head
->
next
;
while
(
cur
)
{
RandomListNode
*
tmp
=
cur
->
next
;
cur
->
next
=
tmp
->
next
;
if
(
tmp
->
next
)
tmp
->
next
=
tmp
->
next
->
next
;
cur
=
cur
->
next
;
}
return
res
;
}
};
```

0139-Word-Break/Article/0139-Word-Break.md
0 → 100644
View file @
f1048508
# LeetCode 第 139 号问题:单词拆分
> 本文首发于公众号「图解面试算法」,是 [图解 LeetCode ](<https://github.com/MisterBooo/LeetCodeAnimation>) 系列文章之一。
>
> 同步博客:https://www.algomooc.com
题目来源于 LeetCode 上第 139 号问题:单词拆分。
### 题目描述
给定一个
**非空**
字符串
*s*
和一个包含
**非空**
单词列表的字典
*wordDict*
,判定
*s*
是否可以被空格拆分为一个或多个在字典中出现的单词。
**说明:**
-
拆分时可以重复使用字典中的单词。
-
你可以假设字典中没有重复的单词。
### 题目解析
与
**分割回文串**
有些类似,都是拆分,但是如果此题采取 深度优先搜索 的方法来解决的话,答案是超时的,不信的同学可以试一下~
为什么会超时呢?
因为使用 深度优先搜索 会重复的计算了有些位的可拆分情况,这种情况的优化肯定是需要 动态规划 来处理的。
如果不知道动态规划的,可以看一下小吴之前的万字长文,比较详细的介绍了动态规划的概念。
在这里,只需要去定义一个数组 boolean[] memo,其中第 i 位 memo[i] 表示待拆分字符串从第 0 位到第 i-1 位是否可以被成功地拆分。
然后分别计算每一位是否可以被成功地拆分。
### 动画描述
暂无~
### 代码实现
```
java
class
Solution
{
public
boolean
wordBreak
(
String
s
,
List
<
String
>
wordDict
)
{
int
n
=
s
.
length
();
int
max_length
=
0
;
for
(
String
temp:
wordDict
){
max_length
=
temp
.
length
()
>
max_length
?
temp
.
length
()
:
max_length
;
}
// memo[i] 表示 s 中以 i - 1 结尾的字符串是否可被 wordDict 拆分
boolean
[]
memo
=
new
boolean
[
n
+
1
];
memo
[
0
]
=
true
;
for
(
int
i
=
1
;
i
<=
n
;
i
++)
{
for
(
int
j
=
i
-
1
;
j
>=
0
&&
max_length
>=
i
-
j
;
j
--)
{
if
(
memo
[
j
]
&&
wordDict
.
contains
(
s
.
substring
(
j
,
i
)))
{
memo
[
i
]
=
true
;
break
;
}
}
}
return
memo
[
n
];
}
}
```

0141-Linked-List-Cycle/Animation/Animation.gif
0 → 100644
View file @
f1048508
128 KB
0141-Linked-List-Cycle/Article/0141-Linked-List-Cycle.md
0 → 100644
View file @
f1048508
# 使用快慢指针求解「环形链表」so easy!
> 本文首发于公众号「图解面试算法」,是 [图解 LeetCode ](<https://github.com/MisterBooo/LeetCodeAnimation>) 系列文章之一。
>
> 同步博客:https://www.algomooc.com
今天分享的题目来源于 LeetCode 上第 141 号问题:环形链表。题目难度为 Easy,目前通过率为 40.4% 。
使用快慢指针的方式去求解
**so easy**
!
### 题目描述
给定一个链表,判断链表中是否有环。
为了表示给定链表中的环,我们使用整数
`pos`
来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果
`pos`
是
`-1`
,则在该链表中没有环。
**示例 1:**
```
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
```
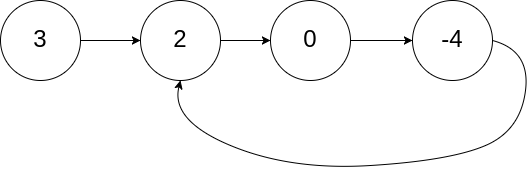
**示例 2:**
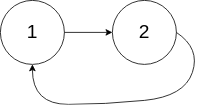
```
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
```
**示例 3:**
```
输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
```

**进阶:**
你能用 O(1)(即,常量)内存解决此问题吗?
### 题目解析
这道题是快慢指针的
**经典应用**
。
设置两个指针,一个每次走一步的
**慢指针**
和一个每次走两步的
**快指针**
。
*
如果不含有环,跑得快的那个指针最终会遇到 null,说明链表不含环
*
如果含有环,快指针会超慢指针一圈,和慢指针相遇,说明链表含有环。
### 动画描述

### 代码实现
```
java
//author:程序员小吴
public
class
Solution
{
public
boolean
hasCycle
(
ListNode
head
)
{
ListNode
slow
=
head
,
fast
=
head
;
while
(
fast
!=
null
&&
fast
.
next
!=
null
)
{
slow
=
slow
.
next
;
fast
=
fast
.
next
.
next
;
if
(
slow
==
fast
)
return
true
;
}
return
false
;
}
}
```

\ No newline at end of file
0144-Binary-Tree-Preorder-Traversal/Animation/Animation.gif
0 → 100644
View file @
f1048508
369 KB
0144-Binary-Tree-Preorder-Traversal/Article/0144-Binary-Tree-Preorder-Traversal.md
0 → 100644
View file @
f1048508
# LeetCode 第 144 号问题:二叉树的前序遍历
> 本文首发于公众号「图解面试算法」,是 [图解 LeetCode ](<https://github.com/MisterBooo/LeetCodeAnimation>) 系列文章之一。
>
> 同步博客:https://www.algomooc.com
题目来源于 LeetCode 上第 144 号问题:二叉树的前序遍历。题目难度为 Medium,目前通过率为 59.8% 。
### 题目描述
给定一个二叉树,返回它的
*前序*
遍历。
**示例:**
```
输入: [1,null,2,3]
1
\
2
/
3
输出: [1,2,3]
```
**进阶:**
递归算法很简单,你可以通过迭代算法完成吗?
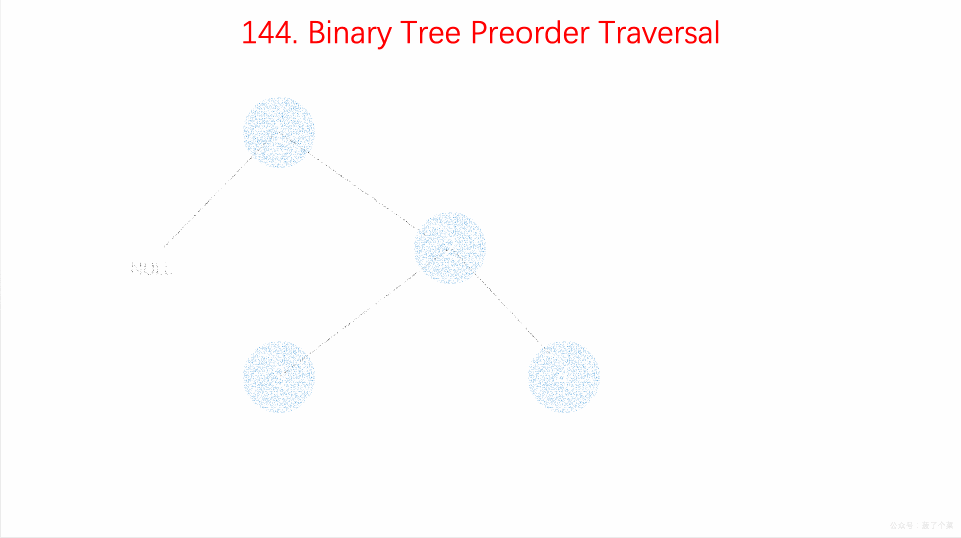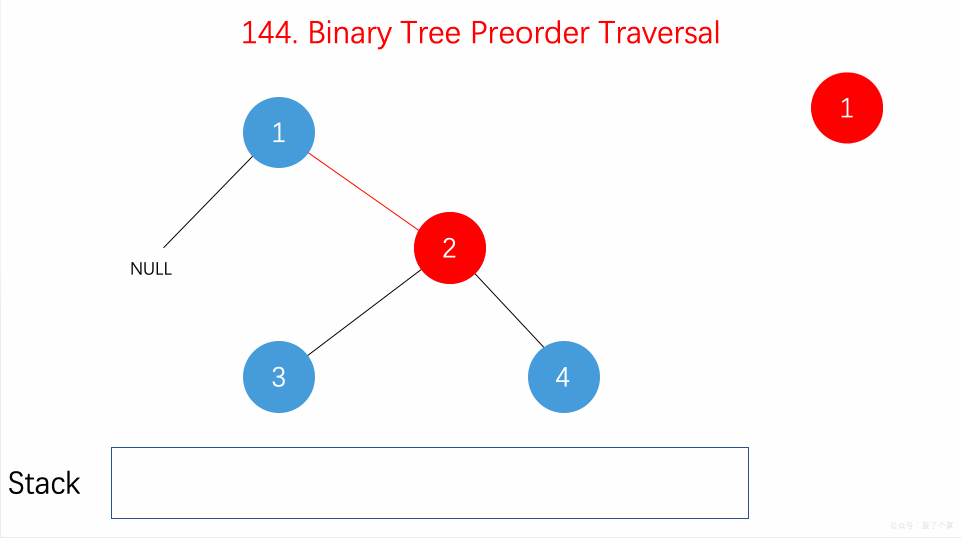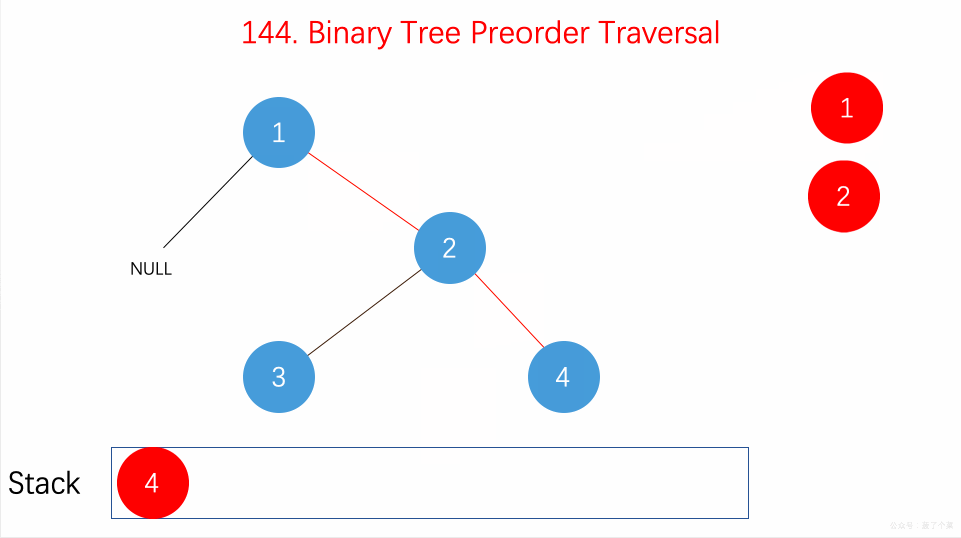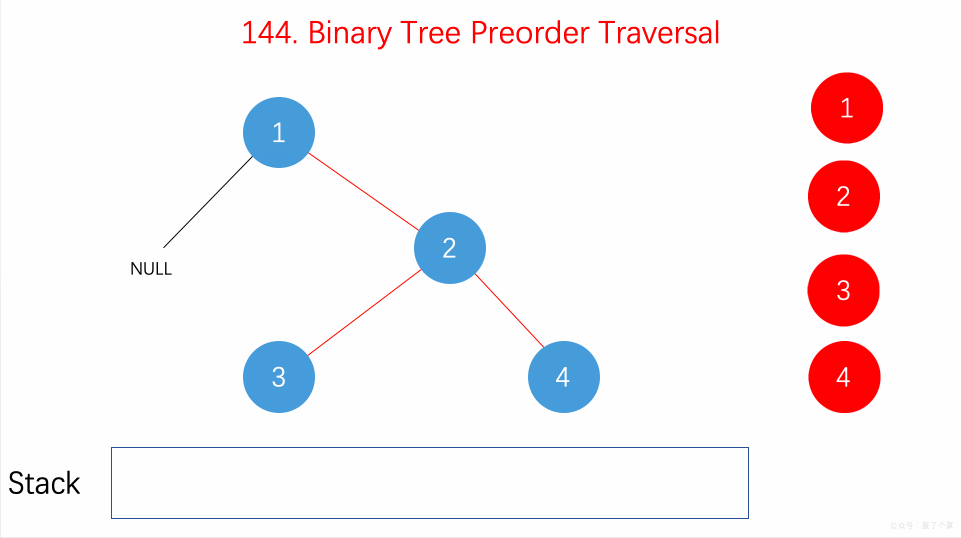
### 题目解析
用
**栈(Stack)**
的思路来处理问题。
前序遍历的顺序为
**根-左-右**
,具体算法为:
-
把根节点 push 到栈中
-
循环检测栈是否为空,若不空,则取出栈顶元素,保存其值
-
看其右子节点是否存在,若存在则 push 到栈中
-
看其左子节点,若存在,则 push 到栈中。
### 动画描述

### 代码实现
```
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
//非递归前序遍历,需要借助栈
Stack<TreeNode> stack = new Stack<>();
List<Integer> list = new LinkedList<>();
//当树为空树时,直接返回一个空list
if(root == null){
return list;
}
//第一步是将根节点压入栈中
stack.push(root);
//当栈不为空时,出栈的元素插入list尾部。
//当它的孩子不为空时,将孩子压入栈,一定是先压右孩子再压左孩子
while(!stack.isEmpty()){
//此处的root只是一个变量的复用
root = stack.pop();
list.add(root.val);
if(root.right != null) stack.push(root.right);
if(root.left != null) stack.push(root.left);
}
return list;
}
}
```

0145-Binary-Tree-Postorder-Traversal/Animation/Animation.gif
0 → 100644
View file @
f1048508
413 KB
0145-Binary-Tree-Postorder-Traversal/Article/0145-Binary-Tree-Postorder-Traversal.md
0 → 100644
View file @
f1048508
# LeetCode 第 145 号问题:二叉树的后序遍历
> 本文首发于公众号「图解面试算法」,是 [图解 LeetCode ](<https://github.com/MisterBooo/LeetCodeAnimation>) 系列文章之一。
>
> 同步博客:https://www.algomooc.com
题目来源于 LeetCode 上第 145 号问题:二叉树的后序遍历。题目难度为 Hard,目前通过率为 25.8% 。
### 题目描述
给定一个二叉树,返回它的
*后序*
遍历。
**示例:**
```
输入: [1,null,2,3]
1
\
2
/
3
输出: [3,2,1]
```
**进阶:**
递归算法很简单,你可以通过迭代算法完成吗?
### 题目解析
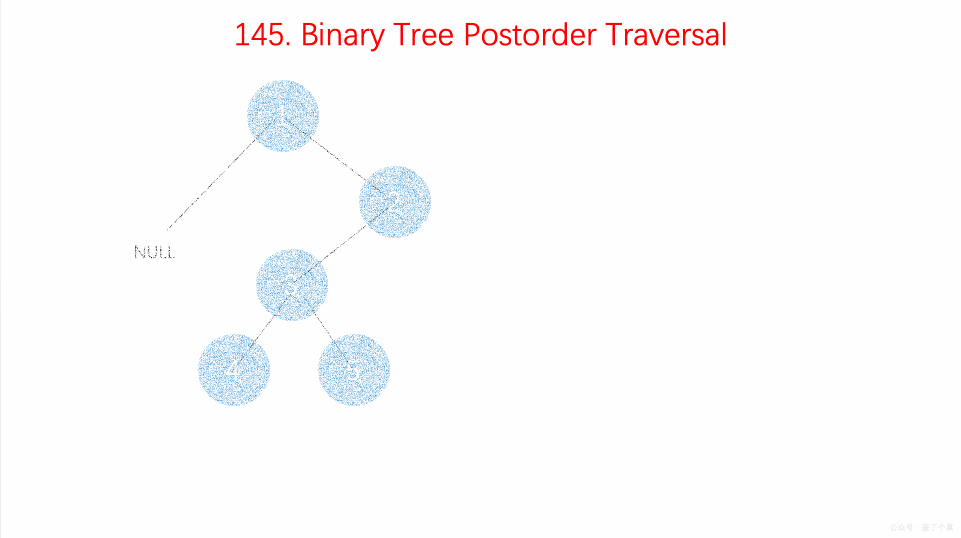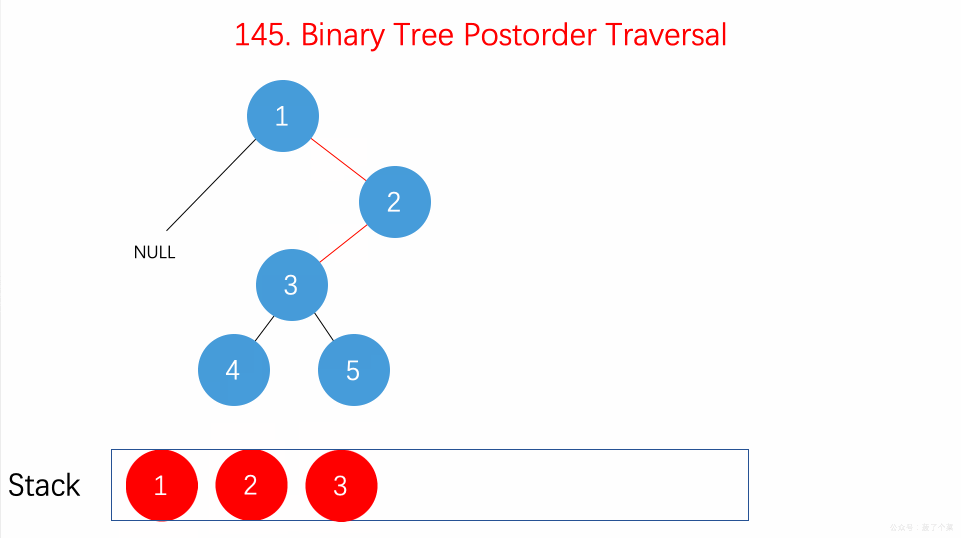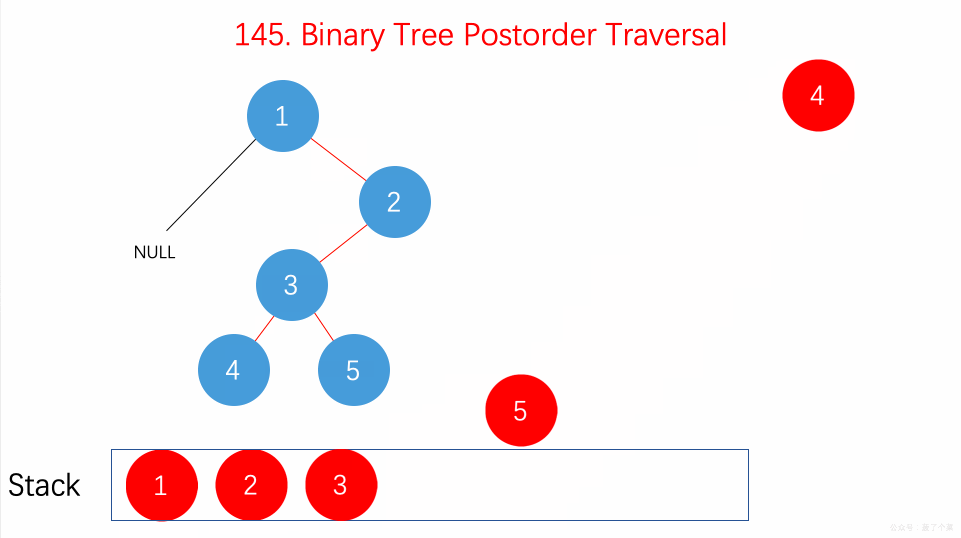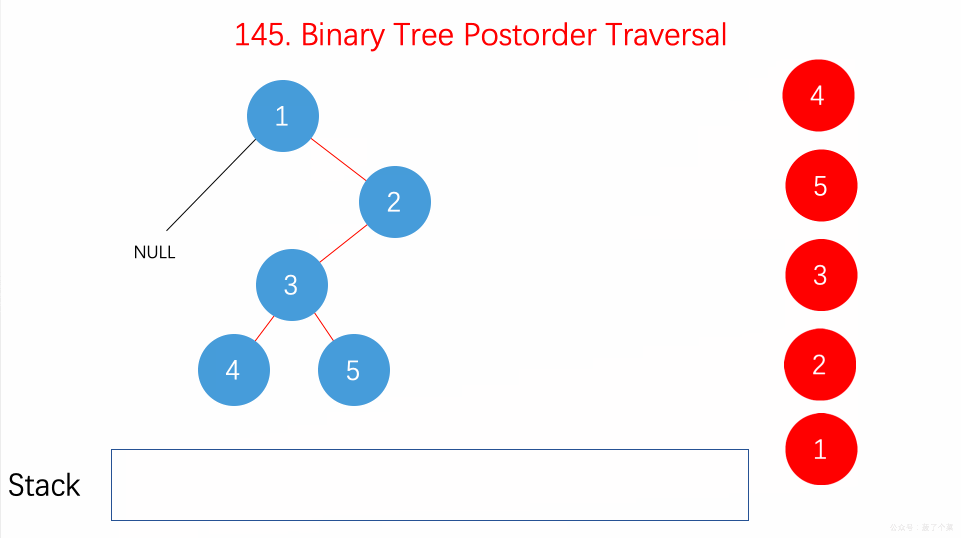
用
**栈(Stack)**
的思路来处理问题。
后序遍历的顺序为
**左-右-根**
,具体算法为:
-
先将根结点压入栈,然后定义一个辅助结点 head
-
while 循环的条件是栈不为空
-
在循环中,首先将栈顶结点t取出来
-
如果栈顶结点没有左右子结点,或者其左子结点是 head,或者其右子结点是 head 的情况下。我们将栈顶结点值加入结果 res 中,并将栈顶元素移出栈,然后将 head 指向栈顶元素
-
否则的话就看如果右子结点不为空,将其加入栈
-
再看左子结点不为空的话,就加入栈
### 动画描述

### 代码实现
```
public class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<Integer>();
if(root == null)
return res;
Stack<TreeNode> stack = new Stack<TreeNode>();
stack.push(root);
while(!stack.isEmpty()){
TreeNode node = stack.pop();
if(node.left != null) stack.push(node.left);//和传统先序遍历不一样,先将左结点入栈
if(node.right != null) stack.push(node.right);//后将右结点入栈
res.add(0,node.val); //逆序添加结点值
}
return res;
}
}
```

\ No newline at end of file
0146-LRU-Cache/Animation/Animation.gif
0 → 100644
View file @
f1048508
5.88 MB
0146-LRU-Cache/Article/0146-LRU-Cache.md
0 → 100644
View file @
f1048508
# LeetCode 第 146 号问题:LRU缓存机制
> 本文首发于公众号「图解面试算法」,是 [图解 LeetCode ](<https://github.com/MisterBooo/LeetCodeAnimation>) 系列文章之一。
>
> 同步博客:https://www.algomooc.com
题目来源于 LeetCode 上第 146 号问题:LRU缓存机制。题目难度为 Hard,目前通过率为 15.8% 。
### 题目描述
运用你所掌握的数据结构,设计和实现一个
[
LRU (最近最少使用) 缓存机制
](
https://baike.baidu.com/item/LRU
)
。它应该支持以下操作: 获取数据
`get`
和 写入数据
`put`
。
获取数据
`get(key)`
- 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据
`put(key, value)`
- 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
**进阶:**
你是否可以在
**O(1)**
时间复杂度内完成这两种操作?
**示例:**
```
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
```
### 题目解析
这道题是让我们实现一个 LRU 缓存器,LRU是Least Recently Used的简写,就是最近最少使用的意思。
这个缓存器主要有两个成员函数,get和put。
其中 get 函数是通过输入 key 来获得 value,如果成功获得后,这对 (key, value) 升至缓存器中最常用的位置(顶部),如果 key 不存在,则返回 -1 。
而 put 函数是插入一对新的 (key, value),如果原缓存器中有该 key,则需要先删除掉原有的,将新的插入到缓存器的顶部。如果不存在,则直接插入到顶部。
若加入新的值后缓存器超过了容量,则需要删掉一个最不常用的值,也就是底部的值。
具体实现时我们需要三个私有变量,cap , l 和 m,其中 cap 是缓存器的容量大小,l 是保存缓存器内容的列表,m 是 HashMap,保存关键值 key 和缓存器各项的迭代器之间映射,方便我们以 O(1) 的时间内找到目标项。
然后我们再来看 get 和 put 如何实现。
其中,get 相对简单些,我们在 m 中查找给定的key,若不存在直接返回 -1;如果存在则将此项移到顶部。
对于 put ,我们也是现在 m 中查找给定的 key,如果存在就删掉原有项,并在顶部插入新来项,然后判断是否溢出,若溢出则删掉底部项(最不常用项)。
### 动画描述

### 代码实现
```
c++
class
LRUCache
{
public:
LRUCache
(
int
capacity
)
{
cap
=
capacity
;
}
int
get
(
int
key
)
{
auto
it
=
m
.
find
(
key
);
if
(
it
==
m
.
end
())
return
-
1
;
l
.
splice
(
l
.
begin
(),
l
,
it
->
second
);
return
it
->
second
->
second
;
}
void
put
(
int
key
,
int
value
)
{
auto
it
=
m
.
find
(
key
);
if
(
it
!=
m
.
end
())
l
.
erase
(
it
->
second
);
l
.
push_front
(
make_pair
(
key
,
value
));
m
[
key
]
=
l
.
begin
();
if
(
m
.
size
()
>
cap
)
{
int
k
=
l
.
rbegin
()
->
first
;
l
.
pop_back
();
m
.
erase
(
k
);
}
}
private:
int
cap
;
list
<
pair
<
int
,
int
>>
l
;
unordered_map
<
int
,
list
<
pair
<
int
,
int
>>::
iterator
>
m
;
};
```

\ No newline at end of file
0150-Evaluate-Reverse-Polish-Notation/Animation/Animation.gif
0 → 100644
View file @
f1048508
357 KB
0150-Evaluate-Reverse-Polish-Notation/Article/0150-Evaluate-Reverse-Polish-Notation.md
0 → 100644
View file @
f1048508
# LeetCode 第 150 号问题:逆波兰表达式求值
> 本文首发于公众号「图解面试算法」,是 [图解 LeetCode ](<https://github.com/MisterBooo/LeetCodeAnimation>) 系列文章之一。
>
> 同步博客:https://www.algomooc.com
题目来源于 LeetCode 上第 150 号问题:逆波兰表达式求值。题目难度为 Medium,目前通过率为 43.7% 。
### 题目描述
根据
[
逆波兰表示法
](
https://baike.baidu.com/item/%E9%80%86%E6%B3%A2%E5%85%B0%E5%BC%8F/128437
)
,求表达式的值。
有效的运算符包括
`+`
,
`-`
,
`*`
,
`/`
。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
**说明:**
-
整数除法只保留整数部分。
-
给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
**示例 1:**
```
输入: ["2", "1", "+", "3", "*"]
输出: 9
解释: ((2 + 1) * 3) = 9
```
**示例 2:**
```
输入: ["4", "13", "5", "/", "+"]
输出: 6
解释: (4 + (13 / 5)) = 6
```
**示例 3:**
```
输入: ["10", "6", "9", "3", "+", "-11", "*", "/", "*", "17", "+", "5", "+"]
输出: 22
解释:
((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
= 22
```
### 题目解析
用数据结构
`栈`
来解决这个问题。
-
从前往后遍历数组
-
遇到数字则压入栈中
-
遇到符号,则把栈顶的两个数字拿出来运算,把结果再压入栈中
-
遍历完整个数组,栈顶数字即为最终答案
### 动画描述

### 代码实现
```
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> nums;
stack<char> ops;
for(const string& s: tokens){
if(s == "+" || s == "-" || s == "*" || s == "/"){
int a = nums.top();
nums.pop();
int b = nums.top();
nums.pop();
if(s == "+"){
nums.push(b + a);
}else if(s == "-"){
nums.push(b - a);
} else if(s == "*"){
nums.push(b * a);
}else if(s == "/"){
nums.push(b / a);
}
}
else{
nums.push(atoi(s.c_str()));
}
}
return nums.top();
}
};
```

\ No newline at end of file
0167-Two-Sum-II-Input-array-is-sorted/Animation/Animation.gif
0 → 100644
View file @
f1048508
67.6 KB
0167-Two-Sum-II-Input-array-is-sorted/Article/0167-Two-Sum-II-Input-array-is-sorted.md
0 → 100644
View file @
f1048508
# LeetCode 第 167 号问题:两数之和 II - 输入有序数组
> 本文首发于公众号「图解面试算法」,是 [图解 LeetCode ](<https://github.com/MisterBooo/LeetCodeAnimation>) 系列文章之一。
>
> 同步博客:https://www.algomooc.com
题目来源于 LeetCode 上第 167 号问题:两数之和 II - 输入有序数组。题目难度为 Easy,目前通过率为 48.2% 。
### 题目描述
给定一个已按照
**升序排列**
的有序数组,找到两个数使得它们相加之和等于目标数。
函数应该返回这两个下标值 index1 和 index2,其中 index1 必须小于 index2
*。*
**说明:**
-
返回的下标值(index1 和 index2)不是从零开始的。
-
你可以假设每个输入只对应唯一的答案,而且你不可以重复使用相同的元素。
**示例:**
```
输入: numbers = [2, 7, 11, 15], target = 9
输出: [1,2]
解释: 2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。
```
### 题目解析
初始化左指针 left 指向数组起始,初始化右指针 right 指向数组结尾。
根据
**已排序**
这个特性,
-
(1)如果 numbers[left] 与 numbers[right] 的和 tmp 小于 target ,说明应该增加 tmp ,因此 left 右移指向一个较大的值。
-
(2)如果 tmp大于 target ,说明应该减小 tmp ,因此 right 左移指向一个较小的值。
-
(3)tmp 等于 target ,则找到,返回 left + 1 和 right + 1。(注意以 1 为起始下标)
### 动画描述

### 代码实现
```
// 对撞指针
// 时间复杂度: O(n)
// 空间复杂度: O(1)
class Solution {
public:
vector<int> twoSum(vector<int>& numbers, int target) {
int l = 0, r = numbers.size() - 1;
while(l < r){
if(numbers[l] + numbers[r] == target){
int res[2] = {l+1, r+1};
return vector<int>(res, res+2);
}
else if(numbers[l] + numbers[r] < target)
l ++;
else // numbers[l] + numbers[r] > target
r --;
}
}
```

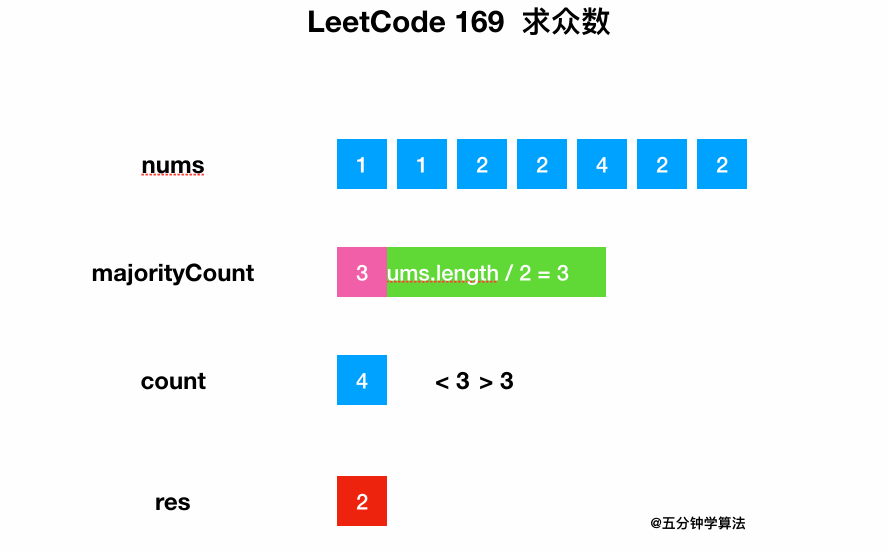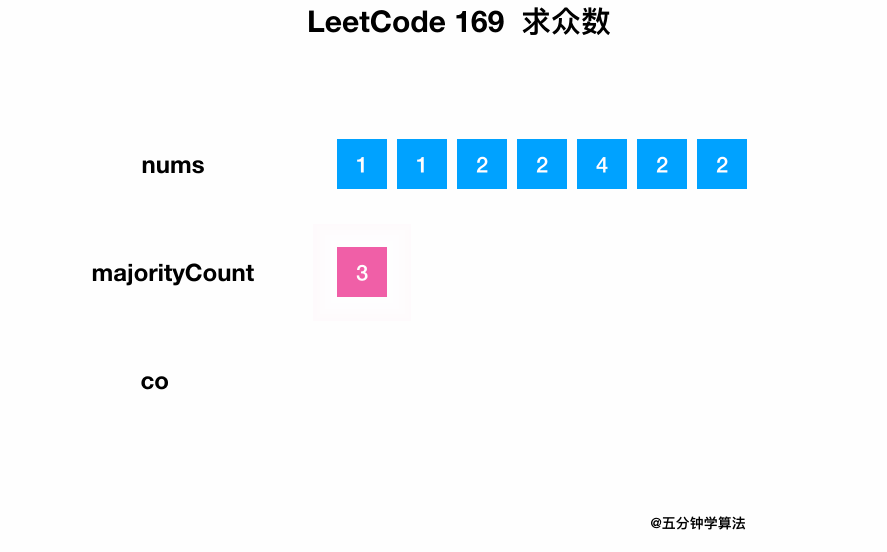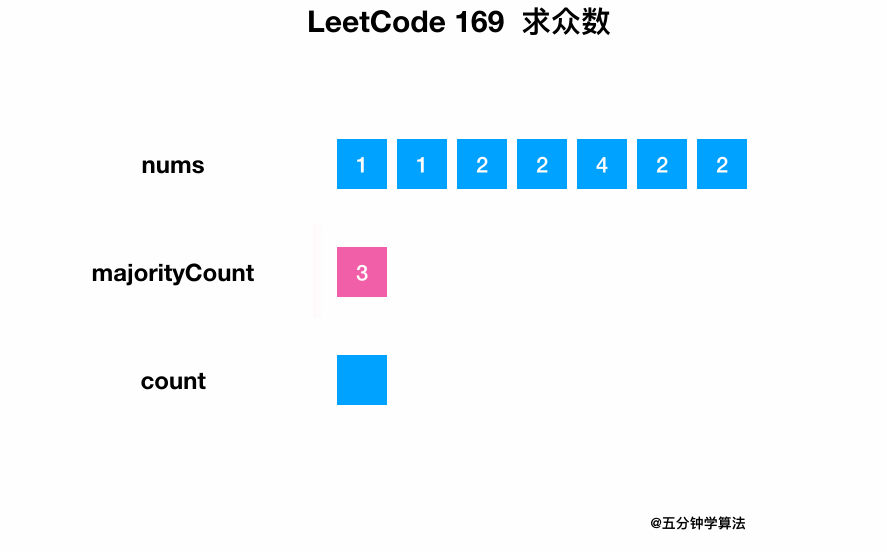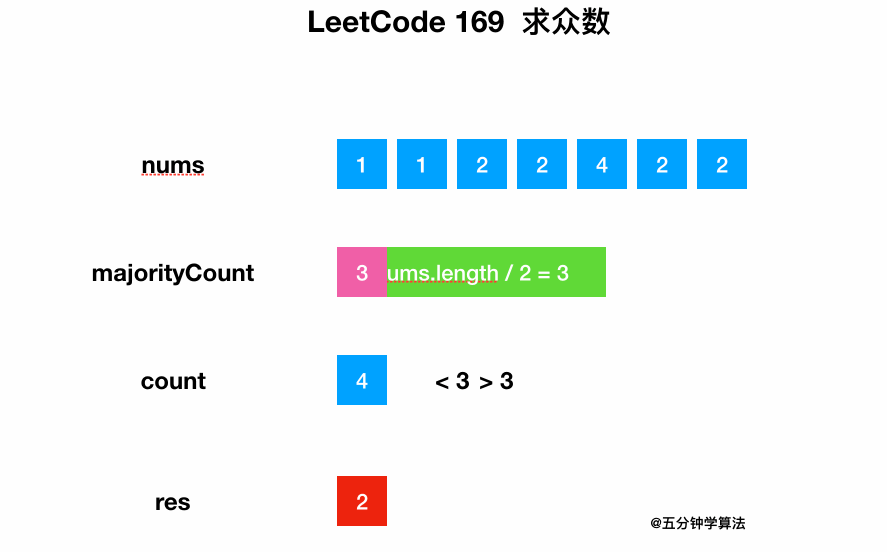
0169-Majority-Element/Animation/Animation.gif
0 → 100644
View file @
f1048508
127 KB
Prev
1
2
3
4
Next
Write
Preview
Supports
Markdown
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

{kind=link}

{kind=link}

{kind=link}